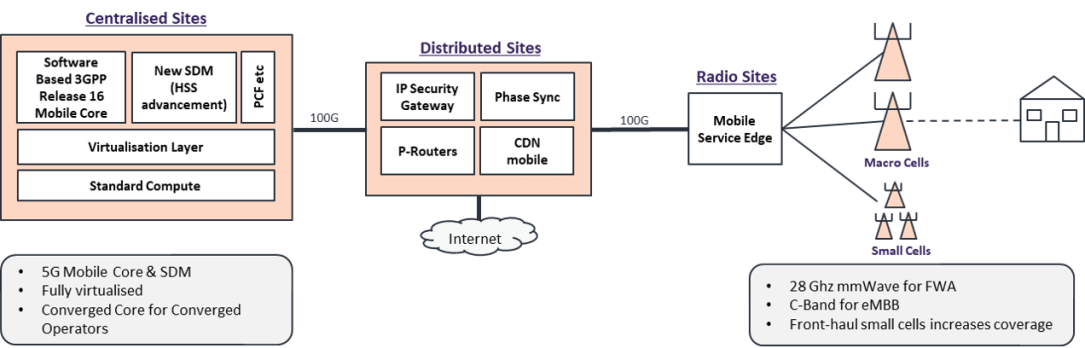
The City of Sacramento has deployed 300+ small cells as part of a 5G Fixed Wireless Access deployment with Verizon. These deployments can only provide partial 5G coverage of a city like Sacramento. This is because of the relative transmission range of 26Ghz and 28Ghz spectrum. In fill is required with further small cells and… Continue reading Guaranteeing Network Slices: The Role of 5G WAN Optimisation for Small Cells