It was a pleasure to be invited to speak again at Google’s Geo for Good event in Mountain View in October 2023.
My talk covered Nature Metrics actionable nature intelligence for the future and the large scale machine learning work we are doing for Species Distribution Modelling.
Introducing A New Organisation to Agile Product Development
As the new CTO, Chief Product Owner, Chief Architect, Lead Engineer or just natural leader it may be your responsibility to introduce an Agile way of working to a new Organisation. We are going to walk through the common steps to successfully introduce Agile methodology and we are going to do it using the most suitable place to introduce Agile which is the launch of a new Product.
I have worked in multiple companies, like BT, Bupa & Vodafone, who have tried multiple times to introduce Agile or one of its familial methodologies. These have varies in success and reach but the thing that most concentrates an organisation is the launch of a new product. This can range from SIM only propositions at Vodafone, 5G network releases at BT and dynamically priced PAYG treatments at Bupa. In each of these cases the product was a massively complex project that could not be delivered without breaking it down into its component parts. Also no one single individual could envisage all the necessary change required and what the end state will actually look like. These products lend themselves to Agile delivery.
I am quite loyal to Atlassian Products so I will be referencing Confluence and Jira liberally in this guide.
Starting with the Product Brief
There are multiple different product brief frameworks and templates available on the internet. Some it’s just easier to search by image to find what you’re looking for. However I have included some templates I have used before as examples.
The core concept of the product brief is that it literally must be brief. It is the elevator pitch of product opportunities. It’s not a manifesto or unchangeable constitutional document that defines the product going forward but the gist of what the product may be. It can be rejected very early on so don’t invest too much effort in it. Though I always recommend keeping a personal record of all your ideas.
The following sections describe the use of PowerPoint and Atlassian Confluence for documenting Product Briefs. Each have their own benefit.
A Simple PowerPoint Product Brief Template
I generally avoid using static documentation tools as they represent a pre-internet way of thinking. Product Briefs however fit quite well in a single slide PowerPoint template. The latter Confluence example is more complex, but a single page can capture the concept of the product.
The Brief template should always first capture the Product or Service Vision. This should be a concise description of the innovation (often the technology) and the benefit which it will bring.
Further sections can include:
detail of the Target Group describing the target market segment (B2C, B2B, B2B2C etc) and who would be the users (often as personas)
detail on the Needs that this product realises by answering the question ‘what benefit is solved by this product’
detail on the Product or Service and a description of how the product aligns with the Business Goals
a high-level competitor analysis is useful whilst remembering that the product can be an improvement of an existing product
any cost estimates at a high level such as potential Revenue and expected Cost Factors can be very useful at an early stage but a Product Brief is never expected to be fully costed as that activity can come out in a later articulation stage.
as I work in R&D some explanation of the Science behind the product helps explain the novelty and costs of the product
Example Product Brief Template
Atlassian Confluence Living Document Approach to a Product Brief
I personally use Atlassian Confluence for all my product design work. I maintain a folder structure in Confluence following The Open Group Architecture Forum’s (TOGAF) Business, Data, Application & Technology format to describe a complete enterprise architecture.
Product Briefs go the under the Business Architecture folder where I provide standard “Templates to be Completed” for all new Product Briefs. Because it is Confluence users have to copy the template and then create a new page under Product Briefs folder in the name of the product. Always remind your users
File structure providing Templates for a Product Brief
The organisations I work with are data centric and a lot of new products have an insights or machine learning capability. For this reason, I include sections in the template to capture the Data and algorithmic parts of the Product. It is beneficial though to keep the product description agnostic to the technology.
Example Product Brief Template Table
Product or Service
An important distinction in a SaaS environment is determining if the product is a single charge product or a recurring charge service. This does not have to be defined in the Product Brief stage but it is useful to get an idea of the nature of the product. A useful lesson I learned whilst working with R&D science start-ups is that the distinction between a product and a service is not clear cut. A science product, like a lab testing function can be expose a set of products with each having a shipped testing kit, imagine lateral flow testing kits. These products are crucial for controlling the rate of infection in a community from Covid-19. The data captured from the mass recording of lateral flow tests provides a set of insights which NHS-Digital (https://digital.nhs.uk/dashboards) used to analyse the R-value transmission rate in the UK. Genetic sequencing provided by NHS labs were able to provide more accurate R-value rates for different Covid variants and used these insights to inform the UK Government of the need for lockdown periods. The insights from these -omics analyses provided crucial insight services and show a data service can be built on top of a science product.
The What, Why & Who of a Product Vision
The vision of a product does not have to be some lofty ambitious epic of a transformational product. But it needs a definition of a What, Why & Who as early as possible. This is really important as otherwise you can rush into a wasted investment.
Personas are a good way of defining the interests of your users and a simple bit of celebrity alliteration (Stormzy the Scientist, Elton the Ecologist) can be a useful way of using characters in your stories. It’s useful to add some further colour to your personas by defining some non work items that they like and dislike. So for Stormzy the Scientist we added that they did not like having to scan barcodes on every sample and liked single click purchase solutions. For Elton we added that he did not like excessive packaging and preferred to order in bulk.
The Why of the Product is critical for understanding the benefit of the product. A recent example of poor understanding of the benefit of a product relates to an international hospital service provider in the UK. This hospital group made the decision to order one million Covid testing kits and four qPCR machines to provide a large testing capability for all doctors, nurses and visiting patients. This procurement activity was made without understanding the digital process for testing. When the solution was launched emails went out to internal staff who all arrived at the testing point at the same time causing a large queue and a potential mass spreading event. They had to go back quickly to the design process to arrange an end to end a registration, booking, sampling and results process to ensure that incoming patients could be properly tested. This design process took a month out of hospital operations during the early stage of the pandemic.
The What of the Product is an articulation of the deliverables and operations of the product. Examining and testing this early will help identify gaps in the product. It is to be expected to have gaps in the product at this early stage and investigation. Modelling the end to end process in a series of workshops will help fill in these gaps. Simple swim-lane process diagrams in Confluence can help articulate the end to end processes that are necessary for linking together stories in Jira at a later stage.
Gating the Product Brief Phase
The product design process is a continual activity and new concepts may arise from all layers of the organisation at any time. The product design process should not be the remit of a select few members of your organisation. Imagination should not be restricted to a strategy department, neither should anything else for that matter.
A gating process is required for Product Briefs where they are reviewed and handled when they are submitted. The gate then approves whether to progress the brief to the next stage or they are rejected early on. The whole process needs to be fast and transparent so that submitters get clear response as soon as possible. The submitter should be invited to the submissions process as otherwise the whole process can seem secret and bureaucratic.
In an agile methodology the aim is to determine success in as few iterations as possible in order to come to the appropriate conclusion. The aim of the product brief gating phase is to select those product briefs with the best hope of success that can be progressed to the subsequent articulation phase. The overhead of the articulation phase is that available resources are provided to support defining the next level of detail.
Articulating the Benefit
In Confluence I provide an articulation template for the next set of detail required. This provides the source of the first set of stories by highlighting and clicking text in Confluence to create Stories under the Product name Epic.
Many organisations skip a formal articulation phase and go straight to Story capture. There is nothing wrong with jumping this stage. My personal preference from working in scientific organisations is that an articulation stage is required to explain the science to the business and the business to the science. This also helps make Confluence more of a document store rather than maintaining assets in Office products. This increasingly becomes useful when Atlassian is your service desk and Confluence becomes your knowledge base for help issues.
The articulation template is more of an architectural high-level design in that it requests details around the Technology, Science (if you work for a lab science business like me), People, Operations, Data & Machine Learning requirements (grouped under Insights) and Finance. Diagrams including wireframes and flows are also useful at this stage so any links to diagramming tools like Miro or Lucid Chart.
A reiteration of the concept, like that in the Product Brief, may seem repetitive at this stage and if the concept has not changed then a link to the Brief can just be provided. Some product concepts may have evolved, and this therefore is a good opportunity to capture that change. Also any further details will help with the articulation of stories which can come from this document.
Articulation Template for Capturing More Detail
Describing Data & Machine Learning Requirements
Agile Machine Learning is a bit of a contradiction as design, training, testing and launch fit a more traditional waterfall approach. Product Management as a discipline sits at the intersection of business need, user experience and technology. A consistent Product Management strategy is necessary for delivering a viable and sustainable product. When the Product Management strategy deviates with every Product Manager hire then the focus and investment can become confused, and you end up a bit like Manchester United. With Machine Learning the requirement for a multi-disciplinary team becomes greater and necessitate ML/Ops, Data Science and hybrid development skills. Again, like Manchester United the hiring of ageing ‘superstars’ is never a good strategy. To be a successful Product Manager with Machine Learning requires flexibility and faith in an iterative process.
I have written on the modelling of Machine Learning operations as a Markov Chain here, as the software delivery model for Machine Learning has a greater number of state transition points than an agile digital delivery.
The epic and stories can frame the Machine Learning problem. The epic must explain the user-centric problem that the Machine Learning problem is trying to achieve. I have worked with 5G radio mast planning designs whilst at BT / EE in the UK. The first 5G sites were costing nearly £500k and had to provide considerable quality of service in dense urban environments. Mobile network planning uses reinforced learning techniques for training and predicting the best deployment model of multiple mobile masts. This is a very human and compute resource intensive process so any optimisation offers considerable benefit.
Machine Learning algorithm selection, in our case this included Artificial Bee Colony algorithms, were the output of a story testing and selecting the most appropriate algorithms during PoC stages. The selection of algorithms were based on comparisons with in-field tests and previous 4G model comparisons. All of this test data was then fed-back into the learning environment.
The nuance from an Agile point of view is that the time taken to attaining an optimal machine learning model cannot be easily predicted and that certain key stories such as model selection and training will run across multiple sprints. Sub-tasks are a good way of documenting the activities for a Machine Learning epic.
One last point to note in any Machine Learning delivery is that research scientists are generally unfamiliar with project management or Agile. In a research institute the time to discovery is does not have a regular cadence. But in a commercial organisation a regular manageable approach is required which can bit chunks out of the greater whole. For this reason, AWS and Azure offer improved visualisation tools for their machine learning capabilities as these lift the point of science away from the necessary infrastructure. If you can break your ML Epics into those that are infrastructure and data based away from those that are training and proof based, then you will be able to achieve success quicker.
Products and services require operational support to deal with imperfections and to keep the customers happy. Don’t launch a product without an operational service wrap but also make sure you start capturing operational requirements at the Product Brief stage, because if you can’t support it then you can’t sell it. Capturing these requirements at an early stage is quite complex if you do not have an existing service wrap. If that is the case then simply document how customer issues will be captured, triaged and supported.
The Operations section of the template asks how the product will be supported. In a lab operations environment, the operational support model includes the processes implemented in the ERP and LIMS (Lab Information Mgmt System). These systems should have their own Standard Operating Procedures. So this section should not be a new domain
Conclusion
Introducing an Agile architecture to an organisation is actually very exciting. One of the most satisfying feelings I’ve ever had at work has been working with floating brain in vat scientists, is when they realise the benefits of Agile for working on a complex problem. There’s an enjoyment no matter your background in drawing UX designs and articulating simple stories. A good buddying system can work well, as an example I have paired an ecology university lecturer with a UX designer to define a geospatial planning application and they paper prototyped a highly intuitive solution. Scientists are very competitive for discovery so adding a quantified competitive element like number of story points designed drives the initial cadence and avoids inertia.
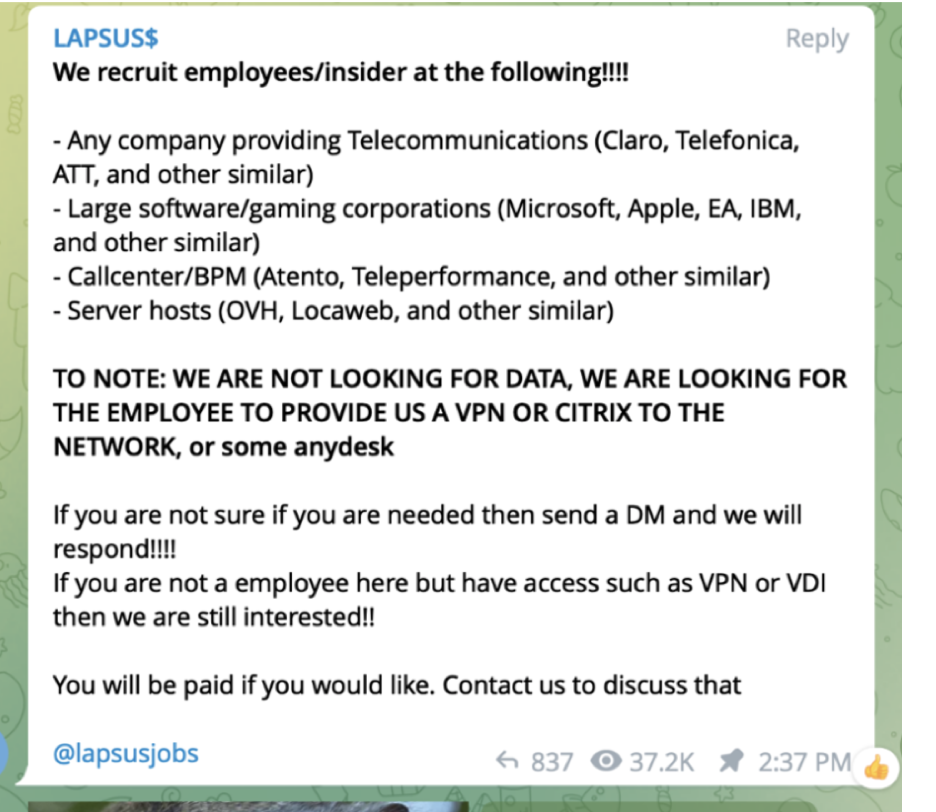
The LAPSUS$ cybercrime group which deleted 50TB of patient data from Brazil’s Ministry of Health have this week disclosed breaches on both Microsoft and Okta. LAPSUS$ are threatening to publish leaked data from Microsoft (source code) and Okta (clients) unless a ransom is paid. LAPSUS$ claim NVIDIA, Samsung, and Vodafone as targets that they have previously successfully breached.
LAPSUS$ use an identity spoofing approach involving SIM Swapping for gaining second factor control of a privileged account. This they achieve by recruiting internal employees at a telecom with the appropriate privileged access to commit a SIM swap. When they are ransoming for millions then $20k is a minimal overhead, but I would be extremely doubtful if they ever paid up!
LAPSUS$ hiring on Telegram
A SIM swap by itself will not lead to a breach as it requires the right individual target and potentially another authentication factor. Let’s therefore look at how SIM Swapping work and the steps necessary to make use of a such a privilege. We will also look at the steps the Chief Information Security Officer should put in place to protect against such low tech / high impact attacks.
What is SIM Swapping
SIM Swapping involves user impersonation to request a SIM change at the Mobile Network Operator but this is harder to do now so scammers are looking at getting the Carrier’s employees to commit a criminal act. Once the scammer has control of an employee then they can target the specific mobile numbers of target individuals for SIM swapping. They can then access the One Time Passcodes necessary to take ownership of a number of services that use SMS as a factor in authentication. It is the responsibility of the Mobile Carrier to prevent such malicious behaviour and should be endeavouring in auditing and social engineering protection for its staff.
Telecoms firms hire thousands of privileged users with administrative privileges in their call centres and central administration centres. A lot of these processes are often out-sourced at lowest possible cost to third parties. Furthermore it is not uncommon for out-sourced processes to be implemented in Robotic Process Automation tools with minimal code reviews potentially allowing corrupt users to leave undetectable backdoors open to key systems. Carriers must enforce good access control and access auditing on major processes that bear a risk for their customers. This means internal fraud prevention must be identifying points of weakness in advance and recognising inappropriate actions as quickly as possible and identifying end users. The TM Forum’s Trust and Security Programme is a good start.
Protect Your System Administrators From Targeted Spear Phishing
As many as 1 in 100 System Administrators could be the victim of Targeted Spear Phishing attacks where they are blackmailed or connived into illegal behaviours. The UK National Crime Agency calculates the number of people in the UK with sexual interest in abusing children at 144,000 meaning that out of 26m adult males in the UK that 1 in 200 male sys admins can be blackmailed. Other threats such as a gambling problems, drug and alcohol dependence, other forms of blackmail cannot be ignored. For these reasons advanced vetting is recommended for all critical System Administrators with significant system access. Basic DBS checks should be the bare minimum. It is not possible to completely possible to remove all TSP attacks, therefore the security architecture must be appropriate and avoid using techniques which can be intercepted.
Switch Off SMS Based Authentication in Preference for Finger Print / Facial Recognition for All Employees
Okta and other Identity Management solutions allow the selection of which MFA credentials they will accept. There are risks with facial recognition and fingerprint spoofing, but these are much lower risks that interceptable SMS and One Time Passcode based MFAs. In the UK over 90% of mobile phone users are Smartphones and the penetration rate is above 100% amongst technologists. It therefore must be mandatory in any organisation that all System Administrators are using fingerprint or “Something You Are” biometric based MFA for privileged access. Remember though that regular password changes are increase the risk of breach as users move to easily rememberable passwords.
Conclusion: Always Have Backups Including Identity Management Platforms
With Dev/Ops and Infrastructure as Code it is possible to have backups to all systems that can be quickly redeployed. Have your architecture team review your systems estate for its complete recoverability so that you always have a fall back option. For transactional items keep a time series store of all transactions for recoverability. And every year run a full disaster recovery scenario planning practice day as a real event to understand as the CISO / CTO / CIO what are your risks.
Product Management as a discipline sits at the intersection of business need, user experience and technology. A consistent Product Management strategy is necessary for delivering a viable and sustainable product. When the Product Management strategy deviates with every Product Manager hire then the focus and investment can become confused, and you end up a bit like Manchester United. With Machine Learning the requirement for a multi-disciplinary team becomes greater and necessitate ML/Ops, Data Science and hybrid development skills. Again, like Manchester United the hiring of ageing ‘superstars’ is never a good strategy. To be a successful Product Manager with Machine Learning requires flexibility and faith in an iterative process. The following is part of my learnings on developing ML products as a CTO with specific focus on Markov Chains, Decision Trees, and Genomics.
A Markov Chain is a mathematical system that experiences transitions from one state to another according to certain probabilistic rules. Markov Chains are regularly used in Algorithms for Reinforcement Learning and specifically within Markov Decision Making Processes, Neural Networks and Supervised Learning. They also make a very good analogy / structure for the different responsibilities of a ‘Product Manager’ working on a traditional non-AI based delivery model versus a Machine Learning Data Centric Product. This is because like a UML State Diagram each node represents a position, and each flow has a weighted percentage for travelling to another state and the probability of transitioning to another state is dependent solely on the current state and time elapsed. A cup competition is a good example of a Markov Chain, a team may have an even probability of moving to the next round (state) or exiting the competition, and each round is not affected by the previous rounds.
A Simple Software Delivery Model represented as a Markov Chain
The primary role of any Product owner is to manage the entire product lifecycle including internal engineer facing and external customer / market facing. Note that the terminology is a bit confusing in ML which is normally viewed as a service, but we will keep using the term ‘Product Owner’ rather than ‘Service Owner’ which always sounds a bit more fixing stuff.
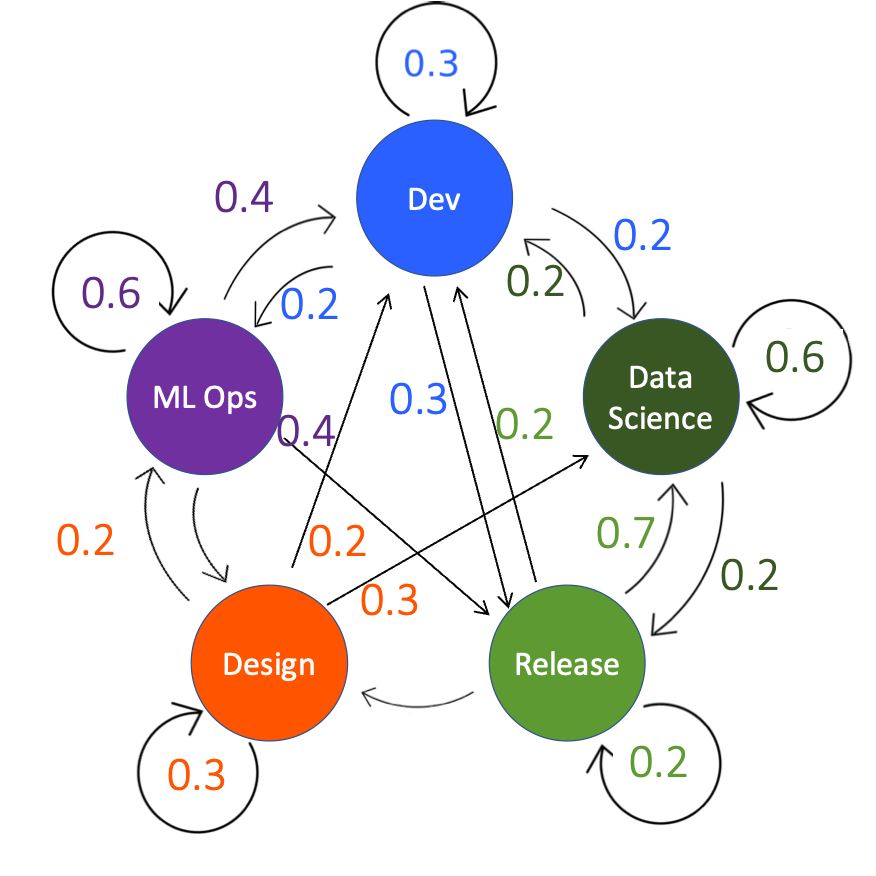
A traditional Product Owner lifecycle as a Markov Diagram would look something like the diagram with states such as Design, Development and Release. Software delivery processes like Lean, Agile and Kanban processes have states and transitions. In your personal delivery model you may choose to add more states, for example Acceptance Test, and between each of these states you would define transitions.
In the example of a non-ML software development model, designs would be released to development as stories 70% of the time but complex design items would stay in design 30% of the time and stories not understood by the developers would return to design 40% of the time. The other transitions are explained by the tensors and weighted by percentages. In the example I have not included a direct flow from Design to Release without going through Development. I have included a link between Release and Design as some items might not meet the customer requirements on Release so could go straight back to Design rather than going back to Development.
With a Markov Chain the probabilities provide a weighting which allows a simple calculation of the efficiency of the model. This make is easy to quantify what percentage of design goes into release with the fewest possible steps. The same can apply to a ML software delivery model with additional states such as Machine Learning Operations and Data Science.
A Machine Learning Software Development Lifecycle represented as a Markov Chain
Machine Learning operations including the management of training data and federated learning is a discipline with its own best practices and career progressions. Machine Learning Operations requires specific skills including Dev Ops environment management for training and production separation alongside other skills such as Information Governance processes for training data. Solutions may have ML Ops as their final state before Release, especially in early product releases. ML Ops may also take responsibility for security and Security by Design is important when working with any form of personal data. Privacy-enhancing technologies and Zero-Trust Frameworks are useful here when synchronous algorithms can be victim to model inversion attacks. When working with Genetic Data (GWAS) and or Polygenic Risk Scores it is important to build a secure platform which encrypts personal data and uses PETs to avoid deducing further personal data from training data and the algorithm.
The Data Science capability can sit within any part of the framework from architecture design, product prototyping, and data wrangling, through to software development. Personally, I have always tried to be both a Data Scientist and a Software Developer throughout my career and I always try to cross-convert development skills with data skills in my teams. Too frequently organisations will silo their engineers. As a CTO I always recommend breaking down artificial barriers between Development and Data. It might seem obvious, but a successful ML Product Manager needs to be good at envisioning the problem and how the ‘Problem’ can be solved by Machine Learning. The Product Manager must be able to translate the business problem that can be solved by Machine Learning. This requires trust with the Data Engineering and Research Science capabilities.
The Design phase of any ML implementation requires a strong and flexible architecture. The same concepts of componentisation, architectural separation, and APIs apply equally to a ML service. Persistence is important for more complex machine learning solutions and wrangling data into the appropriate structure in advance will always be advantageous in a closed loop systems. When dealing with PetaBytes of genomic data for example an appropriate Columnar data structure with metadata stored in a graph or hashmap structure can improve the speed of machine learning.
Lastly, the philosophies of Behavioural-Driven Development (BDD) testing and “Given, When, Then” testing still apply with Machine Learning services. Though it becomes even more incumbent upon the ML Product Manager to work on the problem mapping, together with the architects, so that they are figuring out the present problem and how many of them can be solved using machine learning. You can’t solve all your problems and issues using machine learning. Therefore, a machine learning product manager must be able to distinguish those problems. I personally recommend starting with robust and broad acceptance criteria when training a supervised learning model, such as a decision tree, and then finessing the test cases and the model together with the data scientists. With Genomic datasets and Polygenic Risk Scores the test is a correlation for genetic mappings between SNPs, existing test and peer review frameworks then come into play.
There are 300+ Electronic Health Record systems (e.g. EPIC, PACS etc) in the UK installed within individual trusts, hospitals and surgeries. These systems have poor interoperability, few standard APIs, and view data ownership as belonging to the care provider rather than the individual. The current UK EHR approach is poor for researchers because the lack of APIs and interoperability reduces research’s ability to glean discovery from the widest possible data sets. This impact on research also has a knock-on effect on diagnosis.
An alternative approach is to have the Patient owning their own medical data. This is not a new concept and has been criticised in the past for potentially allowing the hyper scalers (Google, Microsoft, Amazon, Facebook) to own patient data. There can be though a happy medium between EHR centralisation and commercial Health applications. This opportunity is provided by containerisation technologies like Docker and Containerd.
Current Fragmented Situation
The current EHR model in the UK is one of multiple deployments of bespoke non-interoperable solutions across different Trusts, Hospitals and GPs. Data often has to be manually re-entered between systems with a reliance on legacy methods of data transfer. Interoperability cannot be radically achieved in this model as the number of possible integrations becomes the Cartesian product of the number of EHR systems.
Current fragmented Electronic Health Record Systems
The introduction of NHS Number allows the mapping of data between EHR systems. But this form of keying without digital transformation means that the architecture is always in a request and wait approach. The receiver must request the data and await the provider to push the data. With this approach there is no way of discovering what data is available in advance or for verifying the data quality before it is received. This model also has an implicit long request time approach requested between systems. This causes waste in terms of data request times and can detrimentally impact the patient’s quality of care.
Patient Centric Model
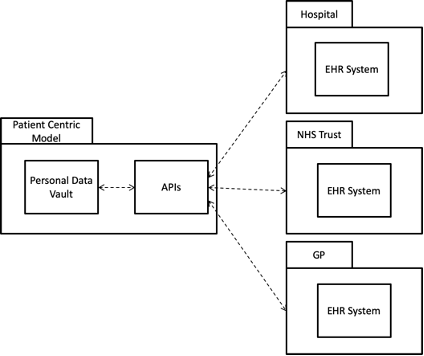
The alternative is a patient centric model. In this approach the Trust, Hospital and GP surgery request from a ‘centralised’ (there can be multiple providers) which provides standard APIs for querying all relevant patient data. The same APIs provide a write-back mechanism. The same Read APIs can anonymise the data so that patients can choose to opt-in for research benefits.
Patient Centric Data Vault integrated with EHRs
In the Patient Centric model all of the patient’s data is held within a personal vault that can only be accessed externally by APIs at the discretion of the patient. The hospital, trust and GP surgery keep their existing EHR solutions in this model and consume the master data record from the personal data vault. The local EHR systems then write their data back to the master source.
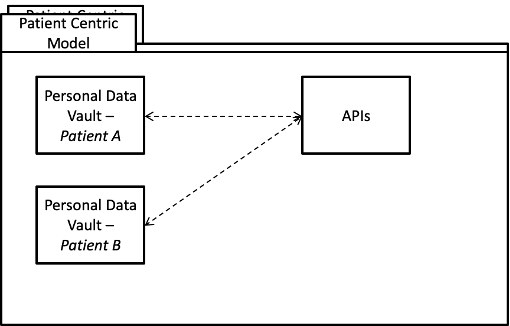
Access control the personal data is provided by a Permissions, Grants and Attestations component. Permission to share and grants always time based and are at the discretion of the patient. Medical institutions can request data with attestations and history stored within the system. Any fraudulent authentication attempts are registered and flagged to the user. The API requests are keyed on multiple attributes including NHS Number, Citizen ID, Staff ID. Research permissions follow the same model with access requests keyed on verifiable research IDs including Institution ID and University IDs.
Structured & Un-Structured Data
Personal data can be held as a series of record ‘bundles’ in a file system format. Data is logically grouped by department definitions and can be extended for other areas such as Research, Demographics and Social Care. This data is accessed by Hospitals, Trusts & Surgeries using the APIs. These APIs provide semantically structured extensible data making use of Graph API technologies which provide the benefit of not requiring versioning.
Data Bundles on a Graph API
The Graph APIs conform to the Open APII standard as expressed with the NHS UK’s Open API Architecture Policy. The APIs provide GET and POST functions for Patient and Record data. The bundle data is encapsulated within these Graph APIs.
The same Graph APIs can support anonymised Research functions for reading available research data. An academic institution would then register for this service and would be provided with a unique key for accessible data. The only accessible data would be the data permissioned by the patient which is discoverable by a final GET Research Available Data service.
Cloud & Containers
The key to this architecture is a cloud deployment of a unique ‘container’ per patient. The container represents a specific file system for each user. The technology used would be an actual Container technology like Docker of Containerd. The container would contain all of the patient data in its local file system.
60 million ‘Containerd’ patient data vaults
With millions of containers the solution needs to optimise the computing resource according to demand. This can be achieved by bringing containers to a hydrated ready state upon demand. To ensure guaranteed data availability all containers will be automatically backed up across two physically different data centres at any one time. All transactional updates will be persisted for 6 months in case of any necessary roll-back.
Conclusion
Building a Patient Centric Model would require centralised funding and competitive tendering allowing for multiple providers to provide services. The total cost would be lower for a majorly improved service than the current distributed EHR model. This approach would also create an internal market of AI driven application and self-care applications that can consume from the Patient API; MyUCLH is such an example.
To recap, there is considerable GDPR, personal analytical, data accuracy, early diagnosis and research benefits from such a model. This approach is conceptually different and would transform the quality of patient data across the NHS. It is implementable on provable solutions that can be reused from industry. It provides benefits to the Patient (proper ownership of data, ability to switch, GDPR), benefit to the NHS (ability to access multiple data, better architecture than any previous data collaboration model), and benefits for Research (access to open data).
The Francis Crick have successfully built a process for Covid PCR testing for patients and NHS Staff. The Crick have also validated a reverse transcription loop-mediated thermal amplification (RT-LAMP) method for 25-minute coronavirus testing. The best way to realise Operation Moonshot is to bring the two processes together and deliver across 200+ NHS trusts.
The following is a costed break-down of all of the necessary components within a solution architecture. I try to provide costed reasoning for all of my assumptions and to use fixed cost points and recent precedent. The costs are broken down into 5 areas: equipment, self-swabbing (as drive thru won’t scale), RT-LAMP testing, IT & processes and rollout. I believe that Operation Moonshot could be delivered for half the UK Government’s initial assessment.
Testing Equipment: The UK Government has already invested in the novel RT-LAMP test capability. The highest throughput machine is the Oxford Nanopore PromethION 48 which can process 15000 RT-LAMP tests a day. Each machine costs just under half a million pounds meaning that handling 10million tests a day would require 667 machines at a non-discounted prices of a third of a billion pounds.
machine list price
£476,145
tests per machine
15,000
tests a day
10,000,000
nhs trusts
220
number of machines
666.67
cost of machines
£317,430,000
cost per trust
£1,442,864
cost per trust for RT-LAMPore machines
Testing Capacity Increase & Self-Swabbing Costs: The UK already has an appointment booking process for the national pillar 2 swab testing. These tests are carried out in car and involve bagging the swabs with pre-registered barcodes. There are 50 test sites in the UK which provide the majority of the UK’s capacity of 350k a day. Increasing the testing capacity to 10m a day would require nearly 1500 sites and tens of thousands of more testers.
current test capacity
350,000
number of test sites
50
site processing capacity
7000
number of sites required
1,429
Drive through testing capacity
The other testing approaches would be either localised testing making use of any medically trained personnel or through self-testing through posted self-test kits. We will examine the self-test model: Based on 10m test a day the whole UK population will be tested each week meaning that everybody in the UK should be receiving a number of tests through the post. Self-testing would have a lower rate of accuracy but this would be mitigated by the sheer size of the testing quorum. The collection of self-tests will need to be within 24-48 hours for the test to be valid and testing centres will be reliant on the immediate return of tests.
tests a day
10,000,000
unit cost per kit
£0.50
daily cost
£5,000,000
kit test cost for 1 year
£1,825,000,000
courier costs per kit
£2.50
daily courier costs
£25,000,000
courier cost for 1 year
£9,125,000,000
total
£10,950,000,000
Self-testing costs
The kit and courier costs of 10m tests a day would be in excess of a £10bn a year even with the lower possible unit prices for kits and couriers. To be cost effective the self-test model would need a local drop-off and collection area to lower the total courier costs. Based on a drop-off model of £10 per 100 tests the yearly cost would decrease to 2bn a year.
tests a day
10,000,000
unit cost per kit
£0.50
daily cost
£5,000,000
kit test cost for 1 year
£1,825,000,000
drop-off courier costs per 100
£10.00
daily courier costs
£1,000,000
courier cost for 1 year
£365,000,000
total
£2,190,000,000
Self-test drop-off costs
RT-LAMP Testing & Results Process: RT-LAMP testing will unpack all self-swab packs and run each sample through the testing lifecycle producing a result within 25 minutes. Test results will need to be validated by medical professionals and positive tests need to be recorded against the summary care record and notified to the relevant Public Health Authority. If each NHS trust would have between 3-6 RT-LAMP machines handling tests and each machine would require a minimum staff of 6 people to continually operate and validate the test results. At an average cost of £40k per FTE this would cost more than £200m per year.
tests a day
10,000,000
nhs trusts
220
RT-LAMP machines per trust
4
trust daily throughput
45,455
daily FTE requirement
24
extra staff requirement
5280
staff costs
£211,200,000
Assessment of staffing costs for handing RT-LAMP process
Central IT Costs, Notifications and Mobile App: The national roll-out of a 10 million a day testing service would be vastly complex, far more complex than mere rocket science! Achieving such a service would require both centralised common processes and local variations to succeed. A good example of local variances would be the designing of the self-swap collection locations. A successful would also need the IT and process functions to be right first time, including the mobile app launch. The IT functions could be realised within a multi-tenanted ITIL compliant solution (e.g. ServiceNow) which would allow centralisation and local variances. Such a solution would also allow for stock and asset management. All test records could be centralised from the RT-LAMP machines and then fed to the relevant PHA’s by integration with the final notifications going to the public via a mobile app. Staffing would manage the end to end processes and the criticality of the data demands a security overhead. It is not unreasonable to include a 30% contingency on the total.
centralised IT process
£5,000,000
localisations budget
£10,000,000
staffing
£2,500,000
mobile app
£2,000,000
PHA integrations
£2,000,000
security
£3,000,000
contingency
£7,350,000
total
£31,850,000
Assessment of IT and process costs
Rollout Process: Rollout costs should be viewed separately as deployments would take time to bed in and would need a degree of local stock and asset management. Precedent suggests that getting to 100k daily tests would have more easily achieved with a lot of small ships rather than following a centralised model. It is therefore not unreasonable to suggest a £10m budget per trust for rollout processes. If the rollout were to include many more smaller GPs then that budget would have to be increased, for this reason I’ve included a 30% contingency.
number of trusts
220
cost per roll-out
£10,000,000
contingency 30%
£660,000,000
total
£2,860,000,000
Roll out costs
Total: The total cost assessment is for one year only but is approximately half of the UK Government’s assessment of £10bn. The most accurate costs are for the Testing Equipment based on the capacity and list prices of the Oxford Nanopore equipment. The self-swabbing approach is based on a collective drop-off solution as otherwise another £8bn could be spent on individual collection of swabs. The RT-LAMP costs as predominantly staff costs for 5000 new staff. The IT costs include a 30% contingency and are based on the UK Government getting its IT right first time. The rollout costs are the the highest individual costs but should be a year one only cost and do not include any economy of scale across multiple NHS trusts who may be able to work together.
Testing Equipment
£317,430,000
Testing Capacity Increase & Self-Swabbing Costs
£2,190,000,000
RT-LAMP testing
£211,200,000
Central IT Costs, Notifications and Mobile App
£31,850,000
Rollout
£2,860,000,000
Total
£5,610,480,000
Total cost assessment
Operation Moonshot has not published any assumptions, cost validation or time period for its £10 billion total cost. The above costs are all based on my recent previous experience of Covid-19 PCR testing. It is not unfeasible that Operation Moonshot could be achieved for half the costs currently being claimed.
There have been 10 UK Government U-Turns so far in 2020. Each change will have had an associated IT change cost. This is my best personal assessment of what each of these changes would likely have cost. I will provide justification for each of my assumptions and will tend towards a lower possible range. I will t-shirt size each U-turn using Low (£500k), Medium (£2-5m), High (£10m) and Very High (£50m+) as thresholds.
U-Turn Number 1: Testing In The Community 12th March – IT cost assessment: Low (circa less than £500k sunk cost)
This U-Turn was a retraction towards testing in hospitals rather than testing in the community. There would have been a ‘sunk’ IT cost for the testing in the community work. This testing would have involved Public Health England implementing a field service for remote swab testing and delivery of those swabs to test centres. The IT required would have extended PHE’s time booking system and resource planning. IT changes to these systems would have had IT costs. As this was scrapped relatively early we can assume that there would have been no further licence of infrastructure costs.
U-Turn Number 2: Face Coverings – IT cost assessment: Zero
No IT changes as this was a policy and information change.
U-Turn Number 3: NHS visa surcharge – IT cost assessment: Medium (£2-5 million sunk cost)
The NHS surcharge has been around since 2015 and is paid when applying for a UK visa. There are a number of applicants who do not have to pay it. The payment method is an online transaction (or cash if from North Korea). The government U-turn means scrapping an existing process and an IT solution that is less than 5 years old. Making the assumption that any online electronic payment solution (at UK government rates) would cost at minimum £0.5m to implement added to the integration costs (£0.75m) with UK visa system and vetting services within (another £0.75m) NHS trusts it is not unreasonable to expect a £2million sunk cost. The service is still available here.
U-Turn Number 4: NHS Staff Bereavement Scheme – IT Cost Assessment: Low (£500k as predominantly configuration changes)
The bereavement scheme, introduced in April, initially excluded cleaners, porters and social care workers. Introducing more groups would have incurred some configuration changes to the claims process and new infrastructure costs. £100k would be a low assessment for implementing these changes.
U-Turn Number 5: MP Proxy voting – IT Cost Assessment: Zero (no actual change)
The government had to U-turn to allow shielding MPs to vote by proxy. The remote proxy voting system will have had an IT cost but as no IT systems were removed there is no sunk cost for this U-turn. The introduction of a secure proxy voting system will have a necessary cost.
U-Turn Number 6: Re-opening schools – IT Cost Assessment: Medium (£2-5m as schools will have scaled IT for different re-openings)
The school re-opening would have forced each individual school to scale its IT solutions according to the expected demand. Centralisation of IT across the UK’s 33,000 schools provides an economy of scale but there will still have been significant unnecessary overspend caused by a late U-turn.
U-Turn Number 7: National school meal vouchers – IT Cost Assessment: Medium (£2-5m for claims process and roll-out)
The introduction of a national school meal voucher system required an immediate build of an IT claims and spend system. It will also have required IT investment in each supplier’s ability to scale. As this was predominantly a procedural and sizing change we can assume that the IT impact would have been relative to the size of the roll-out. For this reason I’m assessing this as having a medium impact.
U-Turn Number 8: UK Contact-tracing app – IT Cost Assessment: High (£10m+ major investment on a non-usable disliked technology)
As of June 2020 we know that the cost of the UK tracing app was £11.8m. It is not unreasonable to expect further costs to have been spent on testing across the Isle of Wight and preparing for national rollout.
U-Turn 9: Local contact tracers – IT Cost Assessment: Very High (£50m+ with major write-off of a centralised contract tracing service)
The centralised contact tracing model had its own IT solutions which are now inappropriate for scaled local use. The centralised solution had scaled infrastructure and licences for 18,000 users. It would have had a communications service equivalently scaled. The local authority solutions could not have easily been separated from the national solution meaning a lot of new build and completely new infrastructure. The costs would be very high because it has to include the completely throw away nature of the national solution and the costs of multiple stand-alone local authority solutions.
U-Turn 10: A-level and GCSE results – IT Cost Assessment: Medium (£2-5m for building and implementing algorithm and significant testing costs)
The government was forced to act after A-level grades were downgraded through a controversial algorithm developed by the Office of Qualifications and Examinations Regulation, leading to almost 40 % of grades awarded being worse than expected by pupils, parents and teachers. This service would have had to incur a cost to model, develop and test. It would needed to have been developed in less that 3 months and to be applied across a large data set of disparate data feeds. Different algorithms, and builds, would need to have been applied for GCSEs and A-levels.
Conclusion: Total Cost Very High (Low estimate £150m+)
Change is the most expensive process in IT. Fast change is even more expensive. Waste also incurs a missed opportunity cost of what else could be done with the capital investment. It also creates a culture of inefficiency where requirements become designed to handle all possible future change rather than focusing on immediate deliverables. All of these U-turn costs were avoidable. All governments should be held to account on the waste associated with U-turn changes.
I really enjoy working at the Francis Crick Institute and I am really proud to have worked on the SARS-CoV-2 Testing Service. It’s all quite different from mobile networks
Find out how @TheCrick worked with @uclh NHS Foundation Trust and Health Services Laboratories to set up a SARS-CoV-2 testing service in just two weeks that has now carried out over 30,000 tests.
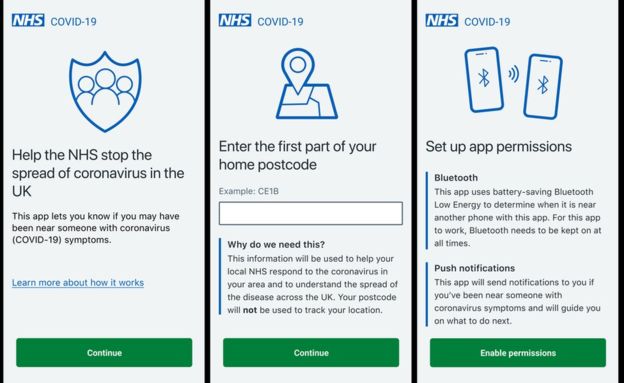
The UK is trialling its Covid-19 contact tracing application which tracks human interactions. The app uses Bluetooth Low Energy (BLE) communications between smartphones for registering handshakes’ duration and distance. This data is then uploaded to a centralised database so that if a user self-registers as Covid-19 positive, the centralised service can push notifications to all ‘contacts’. This is a highly centralised model based around relaying all users ‘Contact Events’ together with user self-assessments of Covid-19 symptoms.
A user can self-report having the symptoms of Coronavirus. They cannot report a positive test for Coronavirus as there is no way of entering either an NHS_ID or a Test_ID. Technically the UK mobile app does not match the mobile App ID against the user’s NHS ID and there is no mapping between the app and NHS England’s Epic system. This approach allows for greater anonymity as the centralised database will not be recording a user’s NHS identifier. The downside of this approach will be a higher percentage of false positives and contact notifications .
NHSX’s Covid-19 App requires GDPR Consent as the legal basis to enable permissions
NHSX and Pivotal, the software development firm, have published the App’s source code and the App’s Data Protection Impact Assessment. The latter is a mandatory document within the EU-GDPR framework. The user provides ‘Consent’ as the legal basis for data processing of the first three characters on their postcode and the enabling of permissions. The NHS Covid-19 app captures the first part of the user’s postcode as personal data. It then requests permissions for Bluetooth connectivity necessary for handshakes and Push notifications necessary for file transfer.
The UK NHS app captures ‘Contact Events’ between enabled devices using Bluetooth. The app records and uploads Bluetooth Low Energy handshakes based on the Bluetooth Received Signal Strength Indication (RSSI) measure for determining proximity. Not all RSSI values are the same as chip manufacturers and firmware are different. The RSSI value differs between different radio circuits. Two different models of iPhones will have similar internal bluetooth components whereas on Android devices there will be a large variation of devices and chipsets. For Android devices it will be harder to absolutely measure a consistent RSSI across millions of handshakes. A Covid-19 proximity virus transfer predictor should take into account the variances between BLE chipsets.
All of the ‘Contact Events’ are stored in the centralised NHSX database. This datastore will most likely hold simple document records for each event, its duration, the average proximity, the postcode (first three characters) only where that occurred and which devices were involved. It will then run queries against that database whenever a user self-registers their Covid-19 symptoms. The centralised server will push notification messages to all registered app users returned in that query. The logic in the server will most likely take a positive / inclusive approach to notification so that anybody within a 2 metre RSSI range for more than 1 second of a person with Covid-19 symptoms will be notified.
All EU countries must comply with EU-GDPR and all are currently launching their Covid-19 tracking applications. These applications because they require user downloading can only use ‘Consent’ as the legal basis for data capture and require a register of the user’s consent. The user must also be able to revoke ‘Consent’ through the simple step of deleting the app on their device. A more pertinent challenge is within a corporate or public work environment where there can be a ‘Legitimate Interest’ legal basis for capturing user’s symptoms. For example a care home could have legitimate interest in knowing the Covid-19 symptoms of its employees. It is likely we may see the growth in the use of private apps encouraged by employers if the national centralised government apps do not reach a critical mass. Either way we live in a smartphone world and bluetooth’s ubiquity is now certain.
The Francis Crick Institute has repurposed its laboratories as an emergency Covid-19 testing facility. The Crick is helping combat the spread of infection and allow key workers to perform lifesaving duties and remain safe.
Crick repurposed PCR testing lab
One of the main technologies the Crick is using in this effort are Polymerase Chain Reaction machines. PCR machines test for the presence of a specific nucleic acid. The end to end process involves capturing molecules on a swab that are then broken down into genetic code, using special chemicals and liquid handling robots. The PCR (polymerase chain reaction) machine can then make billions of copies of DNA strands from the original swab. The PCR machine tests for the presence for the Covid-19 RNA. This is done on a series of 94 Wells (each containing an individual swab) on a Plate within the ThermoFisher PCR machines. The final step involves specialist clinicians making the decision on whether the sample contains sufficient RNA to justify the presence of Coronavirus.
The qPCR test produces a graph showing the exponential progress (or not) of the Cq (Ct) value as it traverses the threshold. The Cq value is the cycle quantification value of the PCR cycle number at which the sample’s reaction curve intersects the threshold line. This value tells how many cycles it took to detect a real signal from your samples. Real-Time PCR runs will have a reaction curve for each sample, and therefore many Cq values. Your cycler’s software calculates and charts the Cq value for each of your sample
Normal Fluorescence Graph in a PCR test
To help support the clinician diagnostic phase we have written a series of complementary tests. These seven tests (github) test each Well, each Plate and a series of Plates. The test data comes from the the ThermoFisher PCR machines and QuantStudio software.
Log score per Well between 90% & 110% Across multiple Plates a value of Rsquared greater than >0.99
Per Well & Multiple Plates
Per Well: Column R in Results Sheet provides efficiency score per WellMultiple Plates: Slope: ~ –3.3R2 >0.99
Seven logical tests implemented in code
The outcome of these tests can then be used in conjunction by the clinician reviewing 94 individual wells (each representing a unique swab). The intent is that this helps reduce human error and can improve the clinical throughput.
The following blogpost explains my experiences with Huawei on 5G for the UK’s largest mobile operator. I was the lead architect responsible for the IT functions for their 5G deployment. I had a relatively close working relationship with Huawei. In summary I did not see any security issues with Huawei beyond the normal human security risks that apply to all vendors. I saw a vendor with strong investments in 5G and with good case studies from existing deployments. The removal of Huawei from the acceptable list of vendors will be to the technical detriment of my previous employer. I have since left BT and now work in biomedical research. My comments here are my own and are not influenced by any other party.
Case For:
In late 2018 BT & EE took the decision to not invite Huawei to respond to our new 5G mobile core RFP. I personally believed this was a mistake, as Huawei were one of the two incumbent suppliers of EE’s 4G LTE network core. EE currently use this 4G LTE network core to support the UK’s Emergency Services Network. I always believe that BT’s fiduciary duty is towards its shareholders and Huawei had provided a reliable & secure 4G core at a competitive price. Removing Huawei from the RFP increased the migration complexity and shrank the pool of possible vendors.
In late 2018 BT & EE took the decision to not invite Huawei to respond to our new 5G mobile core RFP. I personally believed this was a mistake, as Huawei were one of the two incumbent suppliers of EE’s 4G LTE network core. EE currently use this 4G LTE network core to support the UK’s Emergency Services Network. I always believe that BT’s fiduciary duty is towards its shareholders and Huawei had provided a reliable & secure 4G core at a competitive price. Removing Huawei from the RFP increased the migration complexity and shrank the pool of possible vendors.
EE had the relevant software engineering skills to make a relevant technology assessment of any risks associated with Huawei. EE definitely had stronger domain knowledge and technical skills as GCHQ. However, since the acquisition of EE by BT those skills have started to leave the business. BT has been off-shoring key technical roles: preferring to keep its ‘business architects’ on-shore, and to move their technical skills off-shore. This has had an impact that there is now a shortage of on-shore technical skills within BT relating to 5G.
Huawei have invested very strongly in 5G technologies as was evident from previous demos of their technologies I have seen. Their reference case scale is also incredibly impressive: China Telecom are deploying one hundred thousand 5G masts. The equivalent in the UK, would be 5000 masts by the end 2020, and that would be across all four operators. All UK deployments of 5G could have benefitted from this 5G technical domain knowledge sharing.
Case Against:
One argument I have heard is around a 5G security access risk from the user plane accessing a backdoor into the control plane. When pressed this scenario involves a secret code being passed over the network, like a specific ‘secret’ telephone number, that opens a backdoor port into the mobile core. This is spurious for two reasons, the network implements a control plane and user plane split that makes this impossible. CUPS (control user plane split) is also one of the main architectures of 5G. The second reason is that any control to user plane integration would be network monitored and discovered by the operators.
Telecom operators invest in their network monitoring and reporting technologies. These allow the operator to see the heath of the network and to visualise the traffic flows within the network. Access to the internet is always through Internet Peering Points to which the control plane is not connected. If there was an open connection between the control plane and an internet peering point then it would be either monitored or discovered by the mobile operator
A continual security issue is a traditional issue with an industry with so many technologies and processes originating from during the Cold War. This is an issue of spies or operatives working with direct access to the telecommunications network and having the skills to eavesdrop on communications. This will always be a risk but risks can be mitigated by appropriate processes.
Conclusion:
I do not believe the back-door theories spread by certain security experts. The architecture of 5G control user plane split makes any back-door harder to access. Any tracking issues . Human risks are always present but can be mitigated. Access to the mobile core requires vetted clearance and UK tier 2 visas for Chinese workers are for only 3 months so Huawei employees never had direct access to live systems.
What is likely to occur is that telecom operators losing technical skills will become more reliant upon the OEMs for domain knowledge. If the largest OEM is excluded then the operators will either deliver things slower or at greater cost.
In 2017, 22 million people managed their current account on their phone which is predicted to increase to 35 million customers using mobile banking applications by 2023. The mobile phone, rather than internet or retail banking, is also the de facto standard for mobile banking services with more than 250 million Apple Pay users.
UK Open Banking is intended to create a FinTech market
similar to a 1980s consumer credit boom by decoupling the underlying bank from
the service provider. Open Banking promotes an aggregated single view of all of
a customer’s accounts in one place as well as aggregated personal finance and
debt management tools. This creates an opportunity for the Mobile Network
Operator interested in providing financial services without undertaking a full
banking licence.
Open APIs and security are critical to Open Banking. The Open APIs enable third-party developers to extend the services of financial institutions. Open Banking effectively supports and extends the European PSD2 directive, how non-Brexity!. In Open Banking, the UK CMA introduced rules that mean that banks must allow the customer to share their financial information with other AUTHORISED providers. These are known as Account Information Service Providers (AISPs) and are regulated by the FCA. This requirement creates an opportunity for the Mobile Network Operator to either become a Mobile Banking AISP and / or to be a more general provider of Security Services to AISPs and Banks. Both options benefit from specific technologies that the MNO can provide. These include:
a 5G
Network Slice dedicated to “Mobile Banking”
the
exposure of Risk Evaluation services based on fraud prevention and location
data
the
implementation of Passwordless Multi-Factor authentication service
Network services that increase the quality and security of
mobile banking
Users of any service do not like service continuity issues.
This discontent is greater when the interaction is form based and stateful; and
the worry is higher if the session drops during a mobile banking transaction.
For example, it can be peeving when session interruption affects transferring
money whilst in the back of a taxi on the way to an airport. Mobile
applications can handle session management issues more gracefully than mobile
browsers. Nevertheless there will always be customer dissatisfaction
associated with session drops when using mobile banking services.
5G provides improved session and service continuity. One of the key features of a 5G data service is session and service continuity, it ensures uninterrupted service experience to the user regardless whether there is any change of UE (User Equipment) IP address or change in the core network anchor point (4G LTE evolved packet system only provides continuity of IP session). This means that the Mobile Network Operator can provide a chargeable “Mobile Banking” Network Slice; or consume the service itself as a Open Banking service provider.
A 5G Mobile Network Slice dedicated to “Mobile Banking”
can also provide enhanced user security as unique security parameters can be defined for network slices
individually.
Multi Factor Authentication mechanisms provided by the Mobile
Network Operator
The MNO can provide enhanced security based on location based
services (subject to GDPR & customer approval). The MNO can provide a risk
score based on location of the customer.
The Mobile operator knows through the National Device Register if the device has been stolen. The MNO can provide improved 2nd and 3rd Factor authentication protection through the Equipment Identity Register. This is important as finger print spoofing is a known and achievable process; and an amputated digit injected with Botox will continue to provide a useable finger print for two weeks!
Mobile operator understands the roaming likelihood and can
quantify the risk Matching spend and location reduces fraud. Hence the
Apple Pay contactless system does not have a £30 limit. In fact it is even
safer as a physical card can be cloned and a four digit pin can be noticed.
The MNO can also wrap 2nd and 3rd factor
authentication into its mobile app as an identity provider in the Open Banking
universe. And it can provide commercial Risk and Location based APIs consumable
by Open Banking service providers.
How Open Banking Implements
Multi Factor Authentication and Strong Customer Authentication
UK Open Banking can implement Multi-Factor Authentication including Passwordless authentication mechanisms as part of Account Information Service Provider and Payment Initiation Service Provider flows. UK Open Banking uses OAuth 2.0, OpenID Connect and the Financial API specifications from the Open ID Foundation. This extends the PS2 OAuth 2.0 flow where the providing bank must use Strong Customer Authentication to authenticate the user.
This can
be a Username / Password combination or a higher factor of
authentication. More interestingly this can also be Passwordless
(finger-print recognition) authentication by seamlessly pushing
authentication to the bank’s mobile app (if on a mobile device). Alternatively
this push can be to Account Information Service Providers’ authentication
service. The Mobile Network Operator can
be a UK Open Banking Account Information Service Provider using a 3 Factor
authentication in a single passwordless action supplemented by the MNO’s own
location based and fraud detection services
Use of Open Banking in the Internet of Things
The Mobile operator can also support an AISP model when
supporting consumer Internet of Things propositions. As an example, the
consumer with a listed Airbnb property that includes a number of smart devices
may choose to manage the IoT contracts through a separate bank account whilst
managing all their accounts through a single AISP. This creates a nice up-sell
loop for the Mobile Network Operator providing AISP capabilities alongside IoT
propositions.
Conclusion
Trust is critical for the success of mobile banking. Security
breaches can lower the adoption of online banking services. The most effective
mobile banking service is the one that integrates all of the available security
tools together. This is one that the Mobile Network Operator already does well
and can do better with 5G Network Slices and the use of Passwordless 3 Factor
Authentication.
Good Data Governance is required to gather and store customer
consent as part of Auditing phase of implementing Open Banking. The flow to
secure the relationship between the Bank and the Open Banking provider must be
Multi-Factor Authentication mechanism. The only way to make mass market
3-Factor Authentication any stronger is to utilise the MNOs location services.
Finally, Mobile Networks Operators have historically made
poor banks but with Open Banking they do not need to take that long step.
Instead they can aggregate their customer’s existing banking providers through
Open Banking.
As a Google Cloud Platform certified architect I really should blog some more about my actual usage of GCP. One of my favourite tools is Dataproc as it provides a managed Spark & Hadoop environment and enables a lambda architecture suitable for complex network event processing and function remediation.
A mobile radio network is a dynamical system that can be modelled ergodically. Meaning that the radio network performance in geometrical space should be observed and modelled over a period of time. Storing this sort of data requires a geospatial datastore and a timeseries datastore. It is a huge amount of data stored as a nested map. This is why Dataproc’s ability to provide a probabilistic approach to testing a deterministic system is really useful in a remediating / self-healing mobile network.
Apache Spark RDDs
Apache Spark provides the parallel processing of the variant datastores as Resilient Distributed Datasets (RDDs). Modelling the baseline data for geospatial topology, coverage and time-based trials is not trivial. But the fundamental processing of huge datasets for improved RAN distribution is highly challenging but eventually highly beneficial.
The City of Sacramento has deployed 300+ small cells as part of a 5G Fixed Wireless Access deployment with Verizon. These deployments can only provide partial 5G coverage of a city like Sacramento. This is because of the relative transmission range of 26Ghz and 28Ghz spectrum. In fill is required with further small cells and coverage fill is required at mid-band Spectrums like 3.5Ghz.
Sacramento 5G FWA Coverage
The most effective way of delivering backhaul to multiple small cells sites is to use SD-WAN technologies over either Ethernet or microwave links. WAN Optimisation requires an intelligent-path control mechanism for improving application delivery and WAN efficiency. This intelligent path control and management of VPN tunnels needs to be integrated into the network slice management control plane function in order to guarantee the mission critical services.
The Network Slice Management control plane needs to manage end to end the latencies and traffic shaping. To do this the SD-WAN component for small cell backhaul must be an integral part of the end to end network orchestration.
Master Orchestrator Problems
The challenge for telcos face is how to integrate technology specific orchestrators. A 5G SD-WAN small cell solution could involve four unique orchestrators:
small cell orchestrator
with a 5G core orchestrator
a network slice orchestrator (NSSMF)
and multiple existing SD-WAN orchestrators
Most telcos have already deployed a SD-WAN products, involving multiple SD-WAN CPE vendors, where each CPE vendor provides a bespoke orchestrator. Industry examples include, the Cisco Viptela SD-WAN solution which uses a vManage network management solution within the orchestration / management plane and the Nokia Nuage SD-WAN solution that follows the same pattern.
To break this predominance of orchestrators (with lots of compensating logic) it is important to seek integration by API direct to the control plane. To be successful telcos may wish to examine how a vendor agnostic Network as a Service may improve their 5G orchestration strategy.