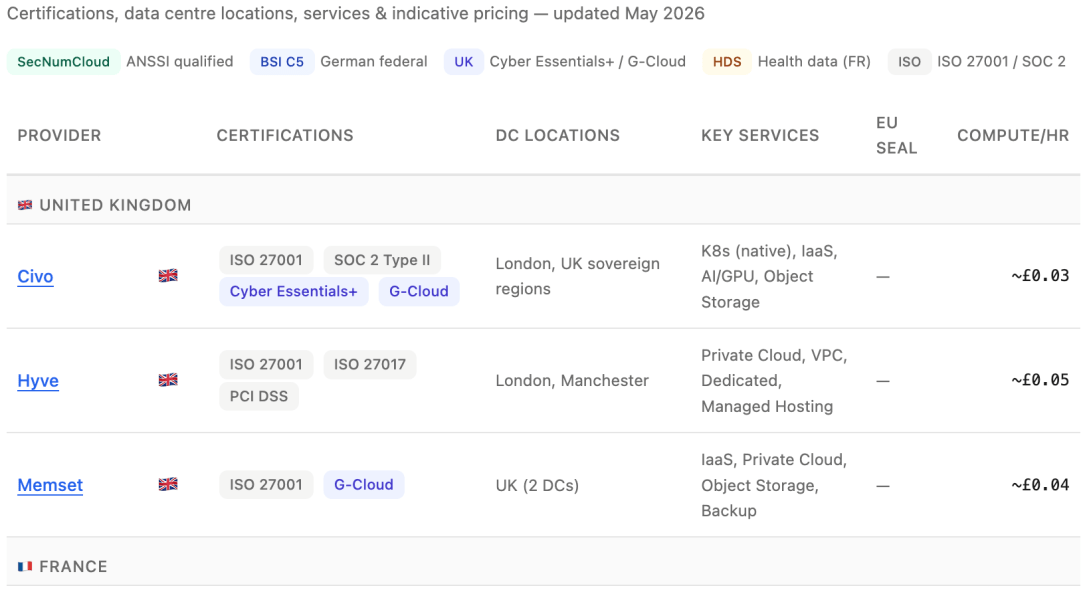
The rule of law is a fundamental principle from the Mesopotanian Code Ur-Nammu, through Magna Carta to International Criminal Court's decisiion to ditch Microsoft Office for European open source alternatives. Data sovereignty requires certainty that services will never be terminated or at the mastery of a governmental body. For this reason I find it useful… Continue reading EU Sovereign Cloud List


